The problem
If you want to buy a bottle of BC wine today, the information you need is scattered across a dozen unconnected websites. Retailers have prices but no reviews. Critics have reviews but no inventory. No single source tells you what's good, what's available, and where to buy it.
We built an AI agent that unifies all of it. Ask a question — "What's a good BC Riesling under $30 that critics like?" — and it searches every major retailer and critic database simultaneously, cross-references the results, and answers with prices, scores, and purchase links. Snap a photo of a wine label, and it identifies the wine and looks it up across every source.
Architecture
The agent is built on LangGraph, an open-source framework for building stateful, multi-step AI applications. At its core, it's a ReAct (Reason + Act) agent: a loop where the language model decides which tools to call, reads the results, and either calls more tools or writes a final answer. The agent uses Gemini 3.5 Flash as its reasoning engine across every node.
A single orchestrator node controls the entire conversation. It reads the user's question, decides which combination of tools to call (often 4-6 in parallel), processes the results, and decides whether to keep searching or respond. There's no rigid pipeline — the agent adapts its strategy to each question. The orchestrator's output is streamed directly to the user as the final answer.
User question (text or photo)
|
v
Validation Gate (off-topic filter)
|
+-- INVALID --> rejection in user's language --> END
|
+-- VALID
|
v
Entry Router
|
+-- (photo attached) --> Vision Node
| |
| extract labels / wine list from image
| |
+-- (text only) -----------+
|
v
ReAct Orchestrator (Gemini 3.5 Flash)
|
+--> Tool calls (parallel fan-out)
| |
| +-- Retailer search (x6 stores)
| +-- Critic reviews (x3 databases)
| +-- Web search (fallback)
| +-- Sommelier reasoning (sub-LLM)
| +-- User clarification (interrupt)
| +-- Preference tracker
|
+--> Loop back (if more tools needed)
|
+--> Final answer --> stream to user
(when no more tool calls)Three components sit outside the core ReAct loop:
- Validation Gate — Before the agent graph starts, a lightweight LLM call classifies whether the query is in scope (wine, pairings, greetings) or off-topic (weather, sports, coding). Off-topic queries get a polite rejection in the user's own language without wasting a full agent run. Response time drops from ~10s to ~2.6s for these cases.
- Vision Node — When the user attaches a photo, an entry router detects the image and sends it through a dedicated vision node before the orchestrator. The vision node uses structured output extraction to read wine labels or parse restaurant wine lists, then folds the extracted text back into the conversation — replacing the image with a compact text representation so the orchestrator works with clean text fields.
- Human-in-the-Loop Clarification — When the query is ambiguous ("recommend me a good wine"), the agent can interrupt the graph and ask the user a follow-up question with clickable option chips, then resume exactly where it left off.
Integrating ten data sources
Each data source presented its own integration challenge. Some offer public APIs. Others require paid subscriptions that we maintain. The integration patterns range from straightforward REST calls to building a local search engine from structured data.
| Category | Sources | What the agent gets |
|---|---|---|
| Retail inventory | 6 BC retailers | Current prices, stock availability, store locations, staff picks |
| Professional reviews | 3 critic databases (licensed access) | Expert scores, tasting notes, drink windows, value ratings |
| General knowledge | Web search API | Wine education, food pairings, region info |
Working with multiple API patterns
No two data sources work the same way. Some retailers expose clean JSON APIs where a single search request returns structured product data. Others use GraphQL endpoints or e-commerce platform APIs with different query semantics. Some only offer server-rendered HTML, which means parsing the page structure to extract prices and availability. For critic review databases, we maintain paid subscriptions and access data through their authenticated APIs.
The key challenge was performance. When the agent fans out to 6+ sources simultaneously, each with different response times, the slowest source becomes the bottleneck. We run all data fetches concurrently using async HTTP, so the total round-trip time is roughly the speed of the slowest source, not the sum of all of them. For sources where review data requires multiple page lookups, we parallelize those as well — reducing one source from ~30 seconds to under 5 seconds.
Building a local search engine
One of our critic sources publishes Canadian wine reviews in a format that doesn't support real-time search queries. Rather than hitting their site on every user request, we built a local pipeline: a scheduled job collects the data twice per week, and we index it into a SQL database with full-text search.
At 13,500+ reviews, the database handles this comfortably — searches return in under 100ms. It rebuilds automatically on a schedule, so reviews are never more than about 72 hours stale.
Making it conversational
A search engine returns results. A conversational agent understands context. The difference matters when someone says "the second one" or "something cheaper" — references that only make sense in the context of what came before.
Multi-turn memory
LangGraph's checkpointing system gives us conversation memory — each turn's messages are saved to a thread-specific checkpoint. When the user sends a follow-up, the full conversation history is loaded, and the orchestrator can resolve references like "that Pinot Noir you mentioned" or "do they have it at another store?"
We deliberately chose ephemeral sessions: closing and reopening the chat starts a clean thread. An earlier design persisted the thread ID in localStorage, which caused wine context from previous conversations to leak into new ones — someone asking about Riesling would get irrelevant Pinot Noir data from last week's chat polluting the context.
Knowing when to ask
Not every question has a clear answer path. "Recommend me a good wine" could mean anything — red or white? Under $30 or over $100? For drinking tonight or cellaring for five years? Instead of guessing, the agent can pause the graph, ask the user for clarification with selectable option chips, and resume once they respond.
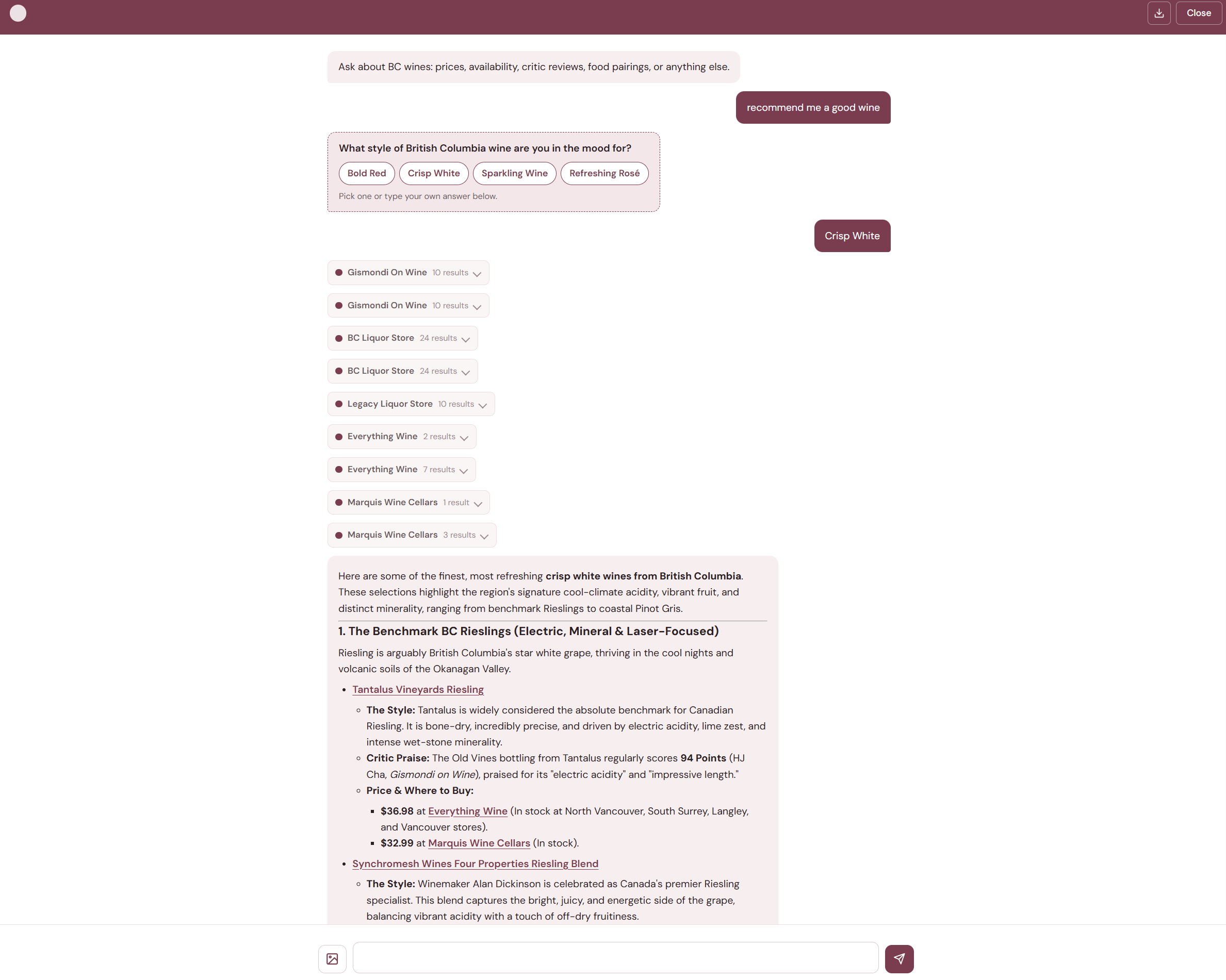


This uses LangGraph's interrupt() primitive. The tool raises an interrupt, the graph checkpoints its current state, and the backend sends the question to the frontend as a special SSE event. When the user responds, the graph resumes from exactly where it stopped — no repeated work. We cap this at 3 clarifications per turn to prevent the conversation from feeling like an interrogation.
The rules for when to ask vs. when to just answer took several iterations to get right. The agent asks when there are genuinely multiple plausible interpretations. It doesn't ask when user preferences or sensible defaults can resolve the ambiguity — if someone says "recommend about 5 wines," that's clear enough.
Reading wine labels and menus
Not every wine question starts with text. Sometimes you're holding a bottle and wondering whether it's worth the price. Sometimes you're staring at a restaurant wine list and want to know which wines are the best value. The agent handles both through a dedicated vision pipeline.
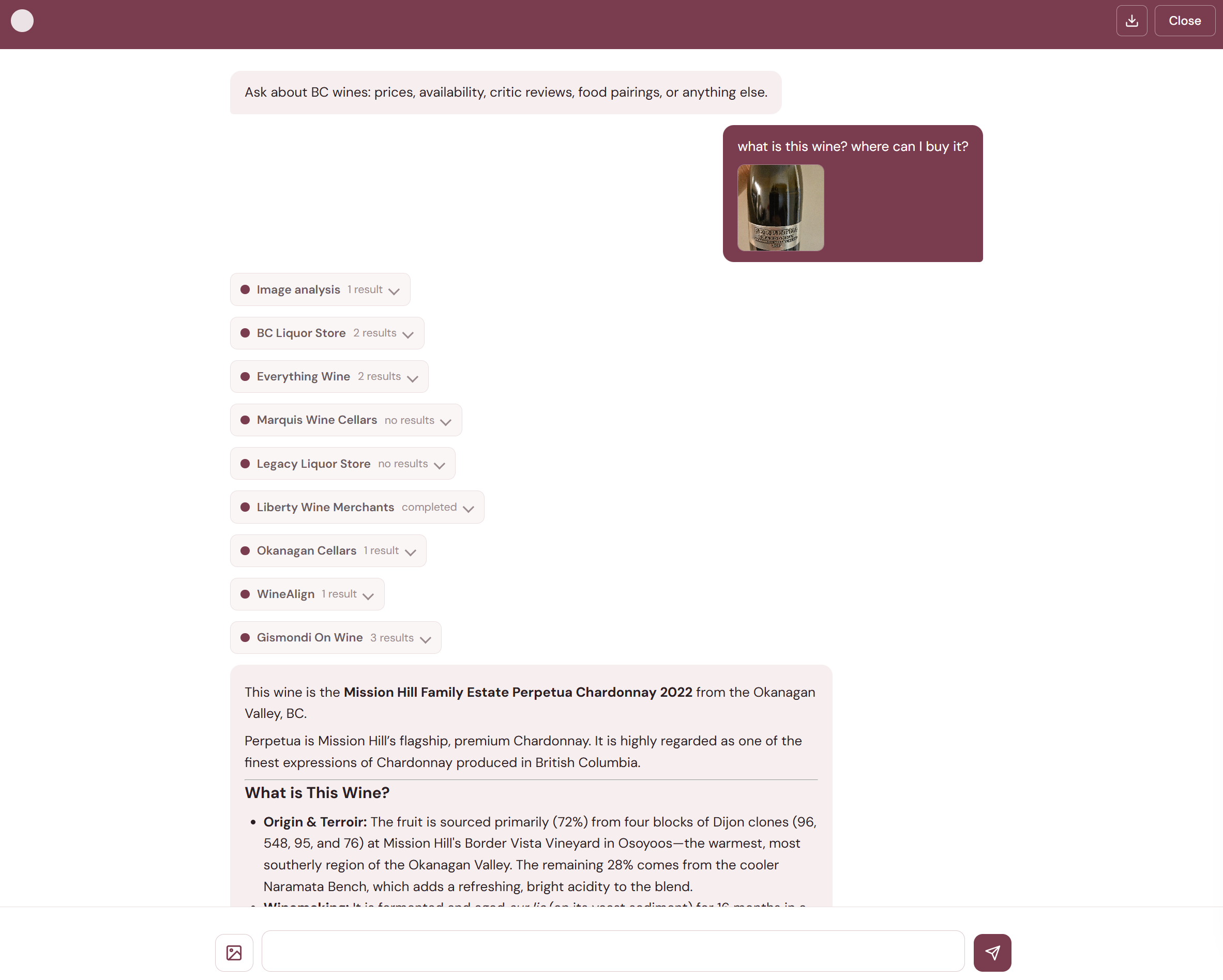
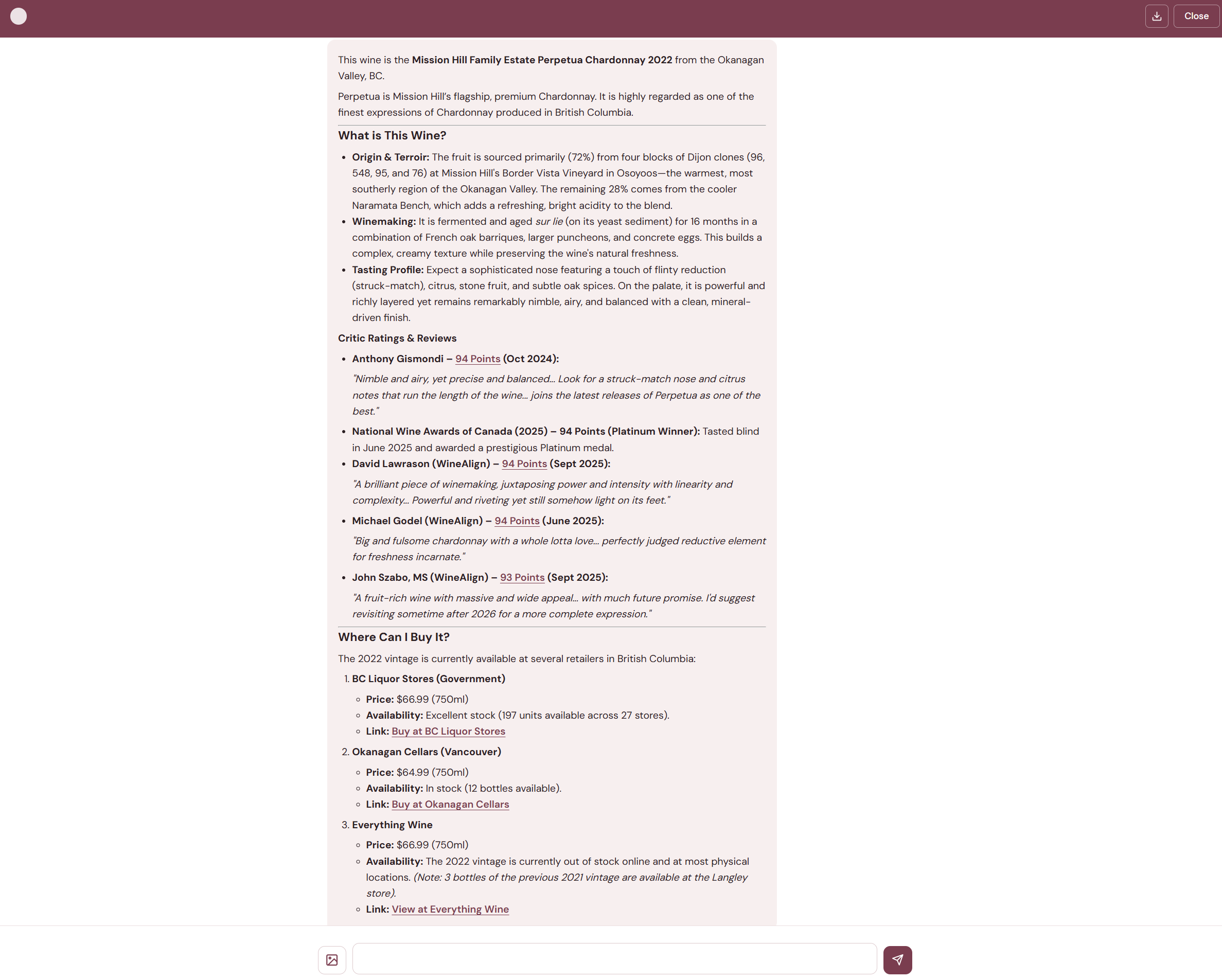
When a user attaches a photo, the frontend downscales it and sends it as base64. An entry router in the agent graph detects the image and routes it to a vision node before the main orchestrator. The vision node uses structured output extraction — not free-form captioning — to pull out exactly the fields the orchestrator needs: producer, wine name, varietal, vintage, region.
The extraction is deliberately conservative: only what is visibly printed on the label, never normalized or translated, null for anything illegible. This prevents the model from hallucinating details that aren't on the label. After extraction, the vision node replaces the image in the conversation with its text representation, so image bytes don't persist in the context window — saving tokens on every subsequent round.
For wine labels, the extracted fields feed directly into the standard search flow — the same retailer and critic tools that handle text queries. For restaurant wine lists, the vision node extracts each line as a separate wine entry, and the orchestrator fans out searches for all of them in parallel, comparing prices, scores, and value across the list.
Keeping the agent honest
For a wine recommendation agent, hallucination isn't just unhelpful — it's actively harmful. If the agent invents a score, the user might overpay. If it fabricates a store URL, the user wastes a trip. We built several layers of defense.
Hard constraints in the system prompt
The orchestrator's system prompt separates rules into Hard Constraints (never violate) and Guidelines (best effort). The hard constraints are:
- Never invent. No producer, vintage, score, price, retailer, or URL may appear in the response unless a tool returned it. If the data isn't there, say so.
- Web search is forbidden for inventory. General web search can return outdated or hallucinated store URLs. It's restricted to educational queries, food pairings, and disambiguation only — all pricing and availability must come from the direct retailer integrations.
- Tool budget limits. Data-collection rounds and total tool calls per turn are capped. This prevents runaway loops where the agent keeps searching because it can't find an exact match. Clarification rounds are tracked separately so they don't eat into the data budget.
Tool error isolation
In the earliest versions, a single tool throwing a runtime error — a network timeout, an authentication failure, an unexpected HTML structure — would crash the entire turn. The user would see nothing.
Now, every tool exception is caught and converted into a structured error result that the orchestrator reads just like a normal result. If one retailer is down, the agent answers from the four that responded. The system prompt explicitly instructs the orchestrator to never abandon a turn because of a partial failure — use what succeeded, mention the gap briefly, move on.
External IP blocking
One lesson we learned the hard way: when your backend runs on a serverless platform like Cloud Run, you don't control your egress IP addresses. Some external websites block entire IP ranges belonging to cloud providers (GCP, AWS, Azure) at the WAF level — and when that happens, there's nothing you can do from your side. No amount of User-Agent spoofing, header manipulation, or retry logic will help. The site's firewall rejects the connection before your request ever reaches the application layer.
We originally integrated another retailer, but their WAF blocked all requests originating from GCP IP ranges. The tool worked perfectly in local development (residential IP) but returned 403 Forbidden consistently from Cloud Run. Because of the error isolation described above, this never affected the user experience — the other sources continued to return results, and the agent composed its answer from what succeeded. But the data from that source simply wasn't available in production.
This is a fundamental constraint of scraping or calling third-party APIs from serverless environments. If you don't have a formal API agreement with the data source, you're at the mercy of their infrastructure decisions.
The interface
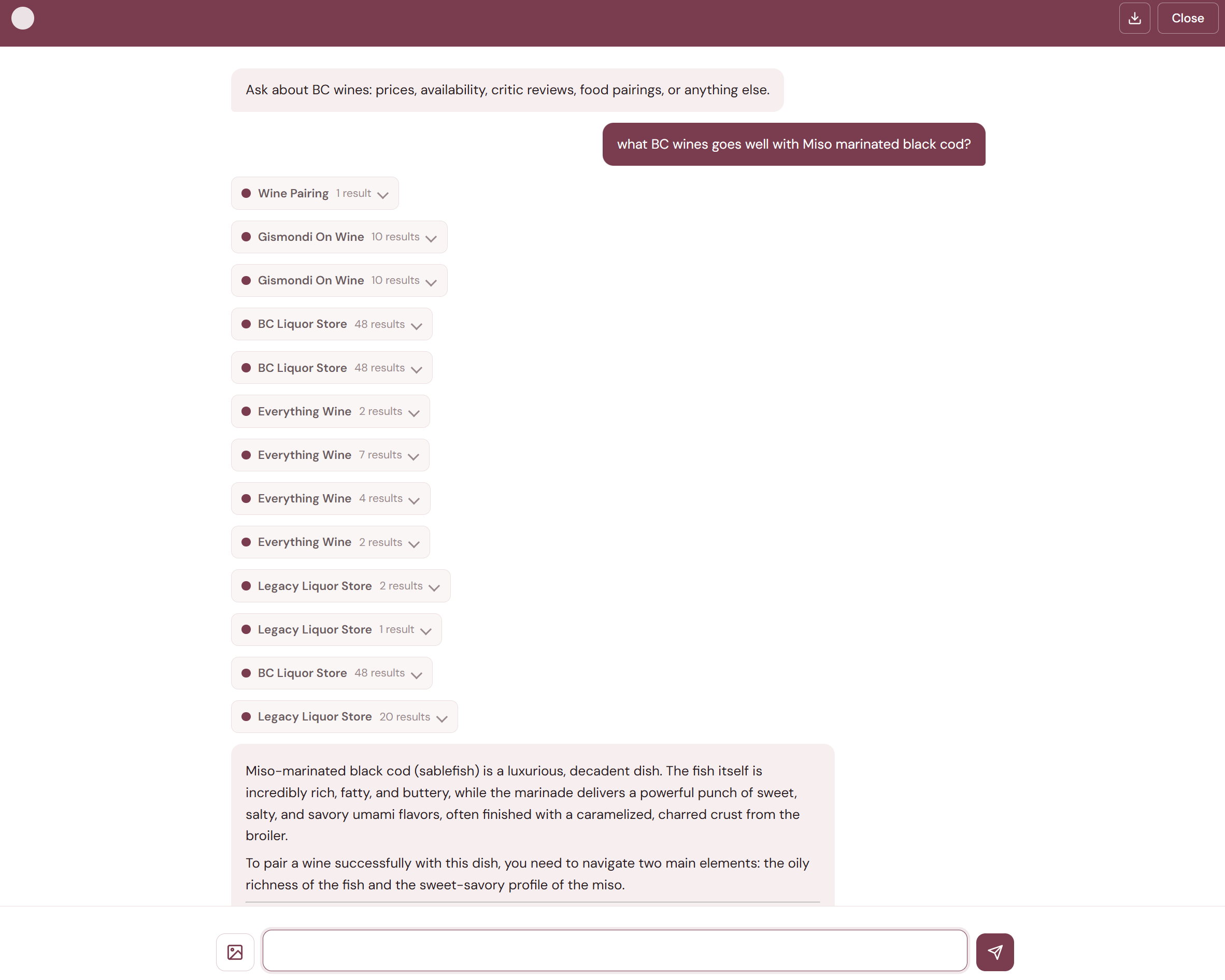
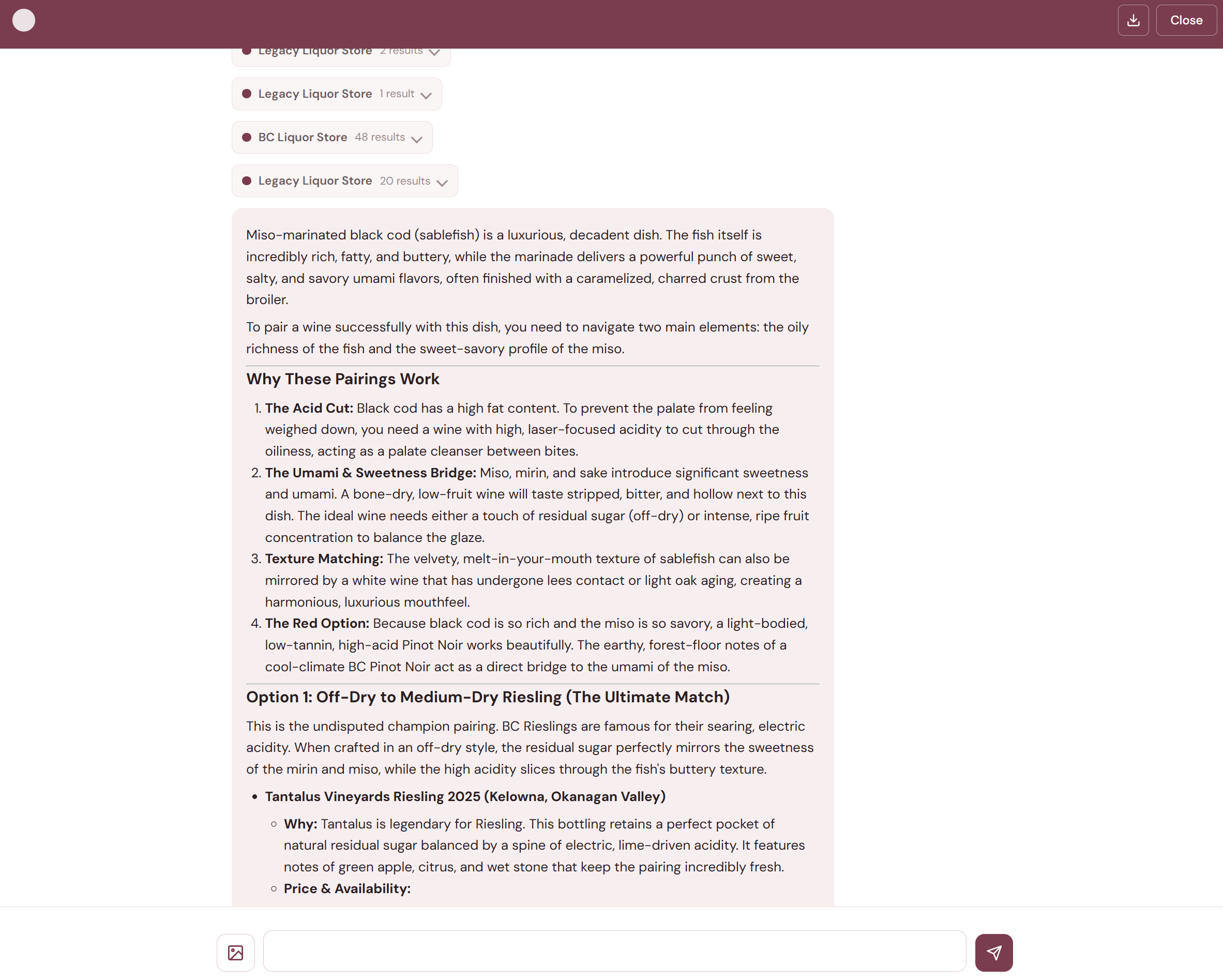


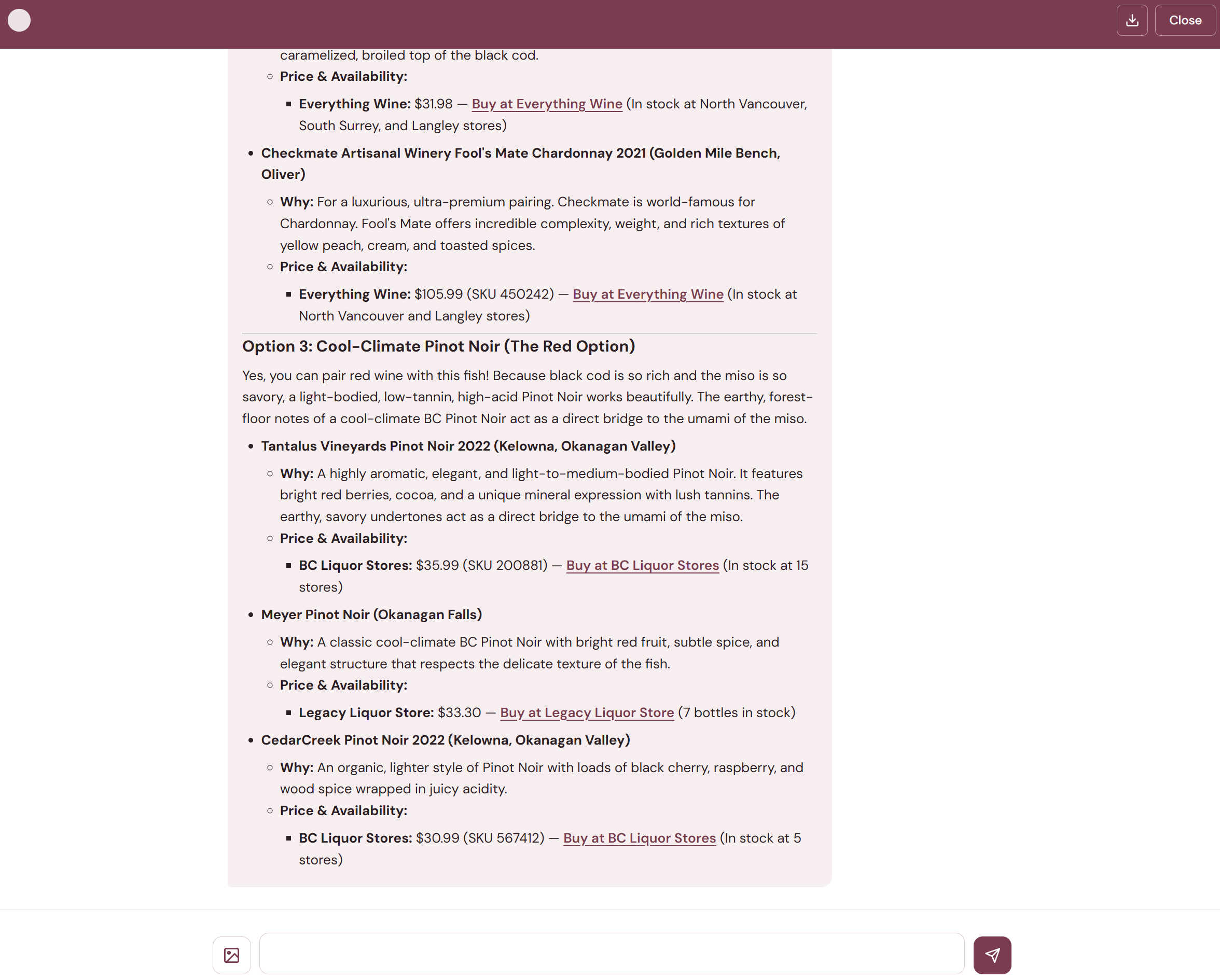
The frontend is deliberately simple — vanilla HTML, CSS, and JavaScript with no build step. The chat interface streams responses via Server-Sent Events (SSE) from a FastAPI backend.
As the agent works, each tool call appears as an expandable badge in the conversation. You can see which sources are being searched in real time, and once results come back, click a badge to preview what was found. This transparency matters — you're not just getting an answer from a black box, you can see the research happening.

The status indicator in the chat header uses a simple visual language: a static dot when idle, a spinning ring when the agent is working. Users can attach wine label photos or wine list images via a file button, drag-and-drop, or clipboard paste — the frontend downscales images to keep payloads reasonable and shows a thumbnail preview before sending.
Example conversation
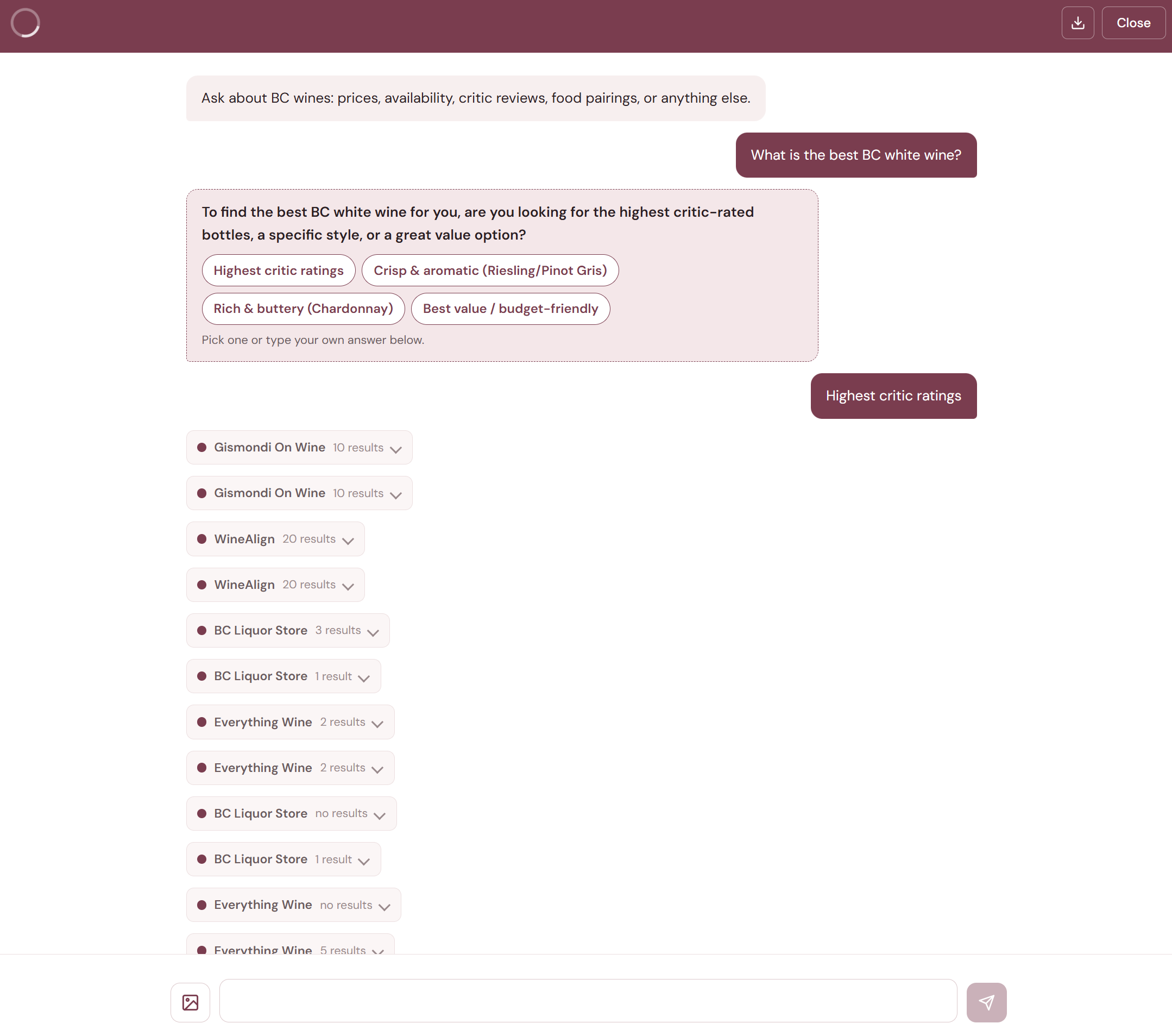
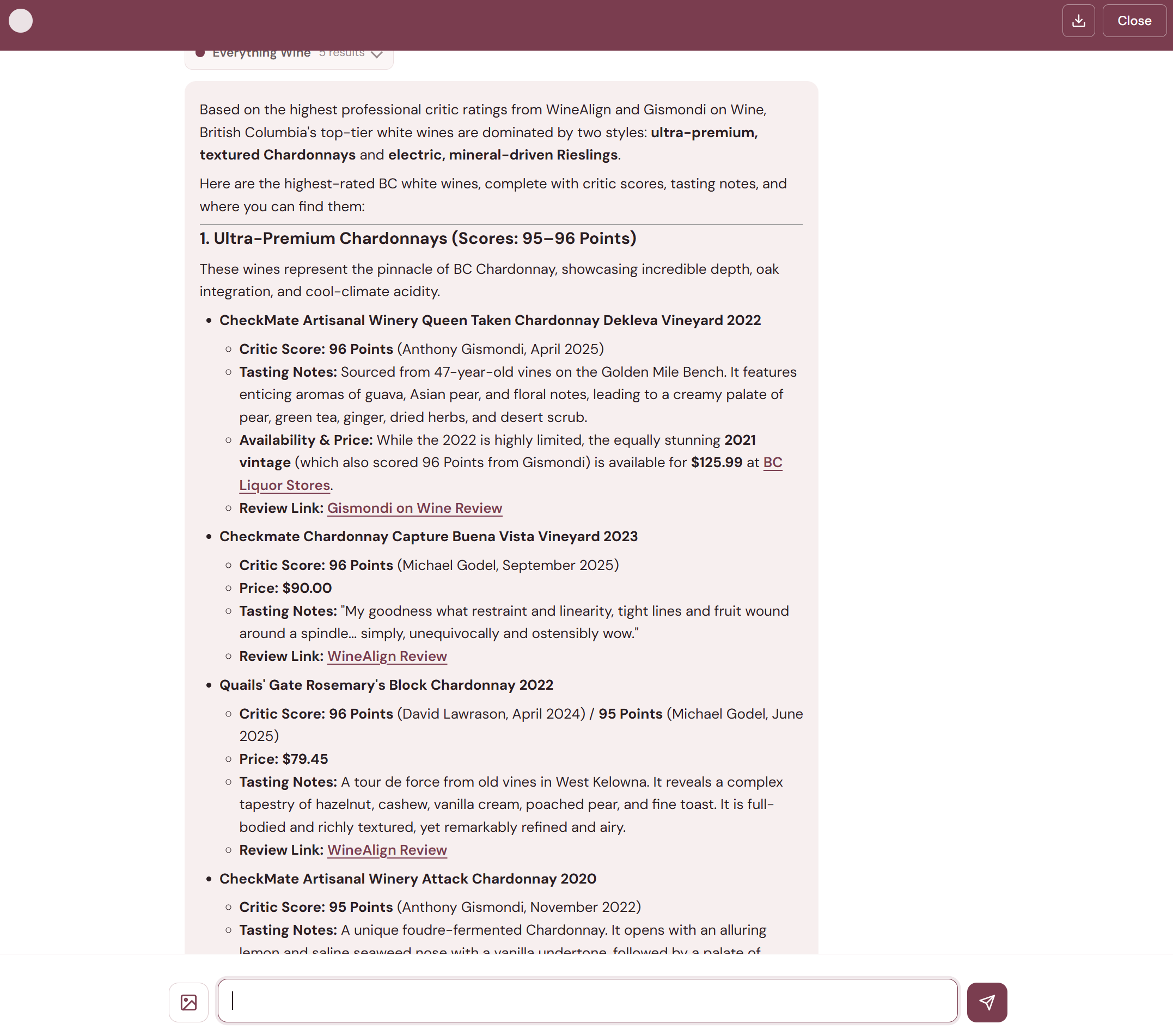

Every conversation can be saved as a PDF using the download button in the chat header. Here's the full output from the conversation above:
Download full conversation as PDF →
Deployment
The agent runs as a split deployment: the static frontend is served by a global CDN, and the backend API runs in a containerized environment that scales to zero when idle. The frontend makes cross-origin API calls directly to the backend, authenticated by CORS origin allowlisting.